April 14, 2026 by The Korea Advanced Institute of Science and Technology (KAIST)
Collected at: https://techxplore.com/news/2026-04-ai-temporal-errors-reliability-medical.html
What if ChatGPT answered with the name of a minister from a year ago when asked, “Who was the minister inaugurated last month?” This is a prime example of the limitations of AI that fails to properly reflect the latest information. A KAIST research team has developed a new evaluation technology that automatically reflects changing real-world information while catching “temporal errors” that may appear correct on the surface. This is expected to drastically improve AI reliability.
New system for testing AI’s sense of time
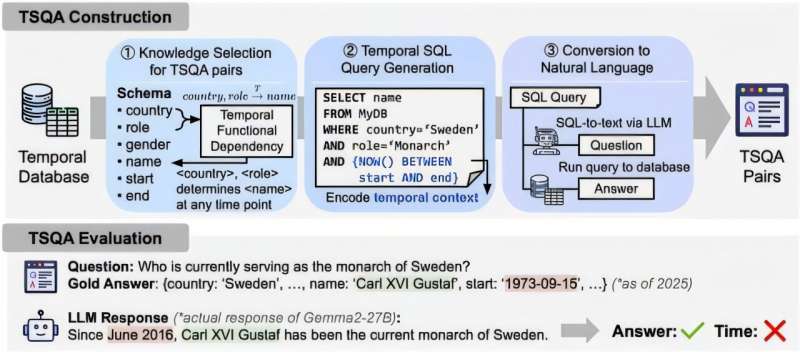
A team led by Professor Steven Euijong Whang from the School of Electrical Engineering, in joint research with Microsoft Research, has developed a system that automatically evaluates and diagnoses the temporal reasoning capabilities of Large Language Models (LLMs) using temporal database technology.
The work, “Harnessing Temporal Databases for Systematic Evaluation of Factual Time-Sensitive Question-Answering in Large Language Models,” is available on the arXiv preprint server.
For AI to earn user trust, the ability to accurately understand real-world information that changes moment by moment is essential. However, existing evaluation methods only checked whether the answer matched or failed to sufficiently reflect complex temporal relationships, making it difficult to properly evaluate various question scenarios occurring in actual environments.
Bringing temporal databases into AI evaluation
To solve this, the research team introduced Temporal Database design theory, which has been verified over the past 40 years, into AI evaluation for the first time. By using the temporal flow and relational structure of data, the core of this technology is the automatic generation of 13 types of complex time-based problems from the database itself, without the need for humans to manually write evaluation questions.
In particular, this technology is evaluated as a major innovation because it shifts from the traditional method where humans manually created problems to a method where evaluation questions are automatically generated based on data.
Furthermore, by automating the entire process from problem generation to answer derivation and verification based on the database, the burden of maintenance can be drastically reduced without the need to manually modify questions as was previously required.
Automatically staying up to date over time
When real-world information changes, the evaluation questions, answers, and verification criteria are automatically updated simply by updating the corresponding content in the database. While the input of the latest information itself is handled by external data or administrators, this technology is structured to perform the overall evaluation automatically after such data is updated.
Additionally, moving beyond the existing method of simply judging whether the final answer is correct or incorrect, the research team introduced a new metric that verifies the logical validity of dates or periods presented during the answering process.
Through this, they achieved a performance improvement in detecting “temporal hallucination” phenomena—where an answer appears correct but has the wrong temporal basis—by an average of 21.7% more accurately than before.
Lower maintenance costs and future applications
Applying this technology can significantly reduce evaluation maintenance costs since only the database needs to be updated when information changes, and it showed an effect of reducing the amount of input data by an average of 51% compared to previous methods.
Professor Steven Euijong Whang stated, “This research is an example showing that classical database design theory can play a crucial role in solving the reliability issues of the latest AI. By converting vast amounts of professional data into evaluation resources, we expect this to become a practical foundation for verifying AI performance in various fields such as medicine and law in the future.”
Publication details
Soyeon Kim et al, Harnessing Temporal Databases for Systematic Evaluation of Factual Time-Sensitive Question-Answering in Large Language Models, arXiv (2025). DOI: 10.48550/arxiv.2508.02045
Journal information: arXiv
Leave a Reply