February 24, 2026 by Ingrid Fadelli, Phys.org
Collected at: https://techxplore.com/news/2026-02-heart-benchmark-ability-llms-humans.html
Large language models (LLMs), artificial intelligence (AI) systems that can process human language and generate texts in response to specific user queries, are now used daily by a growing number of people worldwide. While initially these models were primarily used to quickly source information or produce texts for specific uses, some people have now also started approaching the models with personal issues or concerns.
This has given rise to various debates about the value and limitations of LLMs as tools for providing emotional support. For humans, offering emotional support in dialogue typically entails recognizing what another is feeling and adjusting their tone, words and communication style accordingly.
Researchers at Hippocratic AI, Stanford University, University of California San Diego and University of Texas at Austin recently developed a new structured method to evaluate the ability of both LLMs and humans to offer emotional support during dialogues marked by several back-and-forth exchanges. This framework, dubbed HEART, was introduced in a paper is published on the arXiv preprint server.
“Most recent benchmarks to assess LLM progress have been focused on task-completion and instructional intelligence,” Subhabrata Mukherjee, project lead, Co-founder & Chief Science Officer of Hippocratic AI, told Tech Xplore. “There has been little progress on assessing the emotional intelligence of these models in supportive scenarios. For instance, in health care settings, we expect agents to exhibit trust, rapport, empathy and good bedside manners to connect with human patients.”
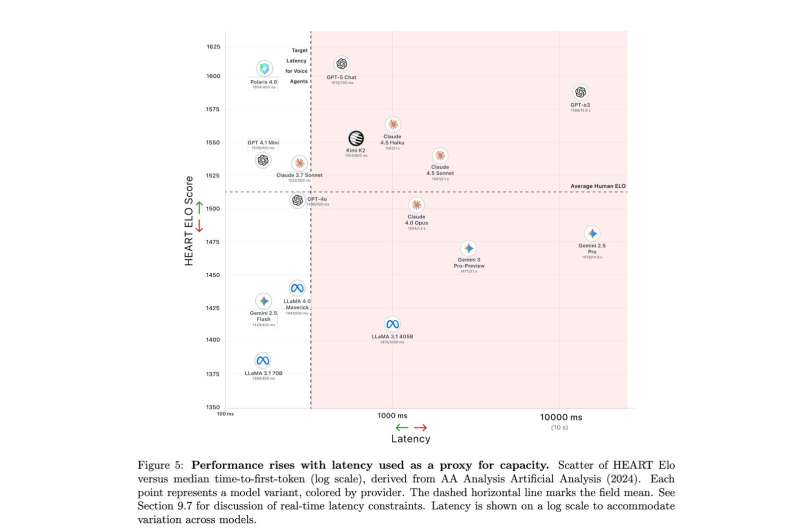
Relationship between HEART Elo score and model latency (time-to-first-token, log scale), used as a proxy for effective model capacity. High HEART performance is correlated with effective model capacity but is not inherently tied to multi-second latency. In our evaluation, the highest-scoring frontier model reaches approximately 1612 Elo at multi-second time-to-first-token, while lower-performing systems cluster near 1385 Elo. By contrast, Hippocratic AI’s Polaris model achieves a HEART Elo of 1604 at a median time-to-first-token of approximately 400 ms, demonstrating that emotionally supportive dialogue quality comparable to frontier systems can be achieved within the latency constraints required for real-time conversational interaction. Credit: Iyer et al.
A five-dimensional benchmark to assess LLMs and humans
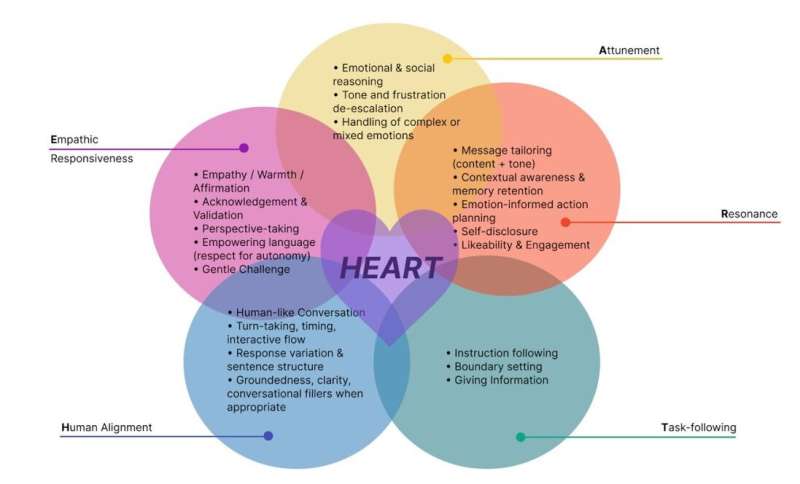
The recent work by Mukherjee and his colleagues was motivated by a need for a reliable benchmark to assess the potential of LLMs for offering emotional support and comparing their supportive skills to the empathy expressed by humans during multi-turn conversations. The framework they developed was dubbed HEART, which stands for Human alignment, Empathetic responsiveness, Attunement, Resonance and Task-following. These are the five dimensions on which the benchmarking method focuses.
“HEART is designed to evaluate whether a response truly feels supportive, conversationally natural, context-aware, and safe,” explained Kriti Aggarwal, lead author and Senior Staff Scientist of Hippocratic AI. “We paired human and model responses to the same scenarios and asked blinded judges who felt more supportive. This allowed us to directly compare humans and models on identical conversations and analyze supportive quality across dimensions.”
A distinctive feature of the HEART benchmark is that it treats emotional support as a multi-dimensional conversational skill that is best assessed in longer multi-turn dialogues unfolding over time. This is in contrast with some benchmarks introduced in the past, which only focused on the supportive language used in individual responses provided by LLMs or humans.
“We show that frontier LLMs often match—and sometimes exceed—average human responses in perceived empathy, with about 80% agreement between human and model judges,” said Aggarwal.
“In addition, we analyze and demonstrate scenarios where human vs. LLM behaviors differ. For instance, humans are stronger at adaptive reframing and nuanced tone shifts, particularly in adversarial turns. HEART provides a practical way to measure deep versus superficial empathy with latency as another dimension that is critical for real-time voice applications.”
Informing the development of increasingly supportive AI
As part of their study, the researchers used the framework they developed to assess the empathy-like skills of an LLM called Polaris, which was developed at Hippocratic AI. Polaris was found to perform remarkably well, producing responses that appeared to convey deeper empathy and were comparable to those generated by other state-of-the-art LLMs, while operating at sub-second latency.
In the future, the HEART framework could be used to assess other LLMs and compare their ability to produce responses that are perceived as emotionally supportive with those of both other AI systems and humans. Meanwhile, the researchers are trying to extend their framework, so that it can also be used to evaluate other types of models, such as multi-modal AI systems and voice-based AI assistants.
“We’re also moving from perceived empathy to experienced empathy, connecting evaluator judgments to how supported users actually feel over time,” added Aggarwal. “In addition, we’re expanding across cultures, recognizing that empathy varies by context. Ultimately, we see HEART not just as an evaluation benchmark, but as a tool to identify which supportive skills matter and how humans and AI can complement each other in delivering care.”
Publication details
Laya Iyer et al, HEART: A Unified Benchmark for Assessing Humans and LLMs in Emotional Support Dialogue, arXiv (2026). DOI: 10.48550/arxiv.2601.19922
Journal information: arXiv
Leave a Reply