November 19, 2025 by Singapore University of Technology and Design
Collected at: https://techxplore.com/news/2025-11-cope-messy-medical.html
Hospitals do not always have the opportunity to collect data in tidy, uniform batches. A clinic may have a handful of carefully labeled images from one scanner while holding thousands of unlabeled scans from other centers, each with different settings, patient mixes and imaging artifacts. That jumble makes a hard task—medical image segmentation—even harder still. Models trained under neat assumptions can stumble when deployed elsewhere, particularly on small, faint or low-contrast targets.
Assistant Professor Zhao Na from SUTD and collaborators set out to embrace this messiness rather than disregard it. Instead of the usual setup where labeled and unlabeled data are assumed to be drawn from similar distributions, they work in a more realistic scenario called cross-domain semi-supervised domain generalization (CD-SSDG).
In this scenario, the few labeled images come from a single domain, while the abundant unlabeled pool spans multiple, different domains, which is exactly the situation many hospitals face.
The team’s findings are detailed in the paper “Dual-supervised Asymmetric Co-training for Semi-supervised Medical Domain Generalization,” published in IEEE Transactions on Multimedia.
Currently, semi-supervised methods typically lean on pseudo-labels. A model trained on the smaller labeled set guesses labels for unlabeled images, then learns from those guesses. When the unlabeled images look quite different from the labeled ones, those guesses skew wrong, and the errors compound.
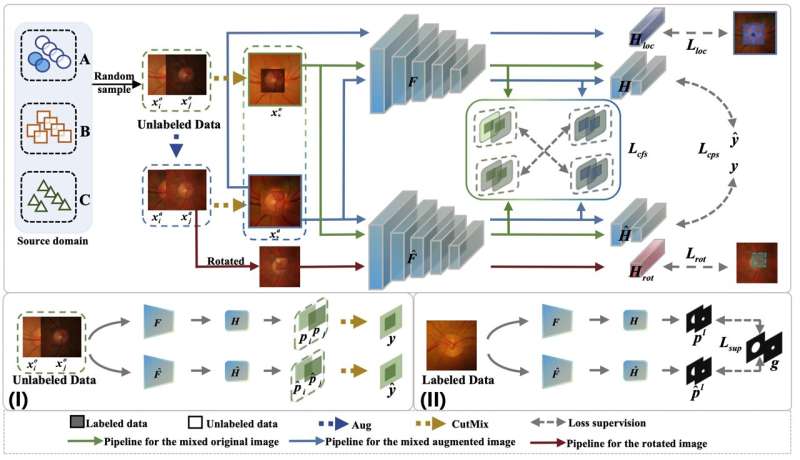
The researchers’ answer is a dual-supervised asymmetric co-training framework, or DAC, where two sub-models learn side by side. They still exchange pseudo-labels, but with a crucial addition: feature-level supervision.
Rather than trusting only pixel-wise guesses, each model also nudges the other to align in a richer feature space, encouraging agreement on underlying structure even when style and contrast differ. The sub-models are also given different self-supervised auxiliary tasks—one learns to localize a mixed patch in a CutMix image; the other learns to recognize a patch’s rotation.
This asymmetry keeps their internal representations diverse, reducing the risk that both models collapse due to the same mistakes and sharpening their ability to separate foreground from background.
“As clinicians and engineers, we rarely get to choose neat datasets,” said Asst Prof Zhao. “DAC is our way of adding a safety net. When pseudo-labels are brittle, feature-level guidance still anchors the model to stable, domain-invariant cues. The asymmetric tasks then push the two learners to see the data from different angles.”
Tested on three benchmark segmentation settings—retinal fundus (optic disk and cup), colorectal polyp images and spinal cord gray matter MRI—DAC consistently generalized better to unseen domains than strong baselines, including methods purpose-built for domain generalization.
Gains were most striking on small or low-contrast structures such as the optic cup, where the team observed double-digit improvements in Dice score over state-of-the-art approaches at low labeled ratios. Crucially, the auxiliary tasks and feature supervision are used only during training, so DAC’s inference cost matches that of conventional models.
“What surprised us was the stability,” added Asst Prof Zhao. “Even as we reduced the labeled proportion, down to a tenth in some settings, the curve didn’t collapse. That gives confidence to hospitals that can label only a small subset each year yet still want models that travel well.”
The team’s approach is also pragmatic. Feature-level supervision acts as a soft constraint that does not depend on precise pixel-wise labels, which are notoriously noisy under domain shift. The asymmetric tasks, mixed patch localization and random patch rotation prediction, are simple to implement (one linear head each) and computationally light, yet they diversify the two learners enough to improve pseudo-label quality over time.
The team also mapped out where DAC can be pushed further. Failure cases include fundus images where multiple blood vessels cross the disk, and scenes where the target almost melts into the background.
Future work includes vessel-aware augmentation for fundus images and adaptive, multi-view representations that combine multi-scale and frequency-domain cues to sharpen boundaries in low-contrast settings.
“These ingredients are not limited to the three datasets we tested,” noted Asst Prof Zhao. “Tumor imaging faces the same twin pressures—expensive annotations and center-to-center variation. DAC is immediately applicable there, especially where precise boundaries are clinically important.”
While DAC is a training-time recipe rather than a brand-new network, its impact is practical—make better use of unlabeled, cross-center data without assuming the world is independent and identically distributed. The method also plays well with existing backbones (ResNet-DeepLabv3+ in the current study) and standard optimizers, keeping the path to adoption short.
The researchers report consistent improvements across Fundus, Polyp and self-supervised contrastive graph matching (SCGM) benchmarks, faster training than a leading co-training baseline and no extra cost at deployment.
“Above all, generalization is the point,” said Asst Prof Zhao. “Hospitals want models that behave when the scanner is different, the patient is different, the lighting is different. By supervising not just the labels we can see, but the features that hold across domains, we move one step closer to that goal.”
More information: Jincai Song et al, Dual-supervised Asymmetric Co-training for Semi-supervised Medical Domain Generalization, IEEE Transactions on Multimedia (2025). DOI: 10.1109/tmm.2025.3613080
Leave a Reply