October 15, 2025 by The Korea Advanced Institute of Science and Technology (KAIST)
Collected at: https://techxplore.com/news/2025-10-federated-ai-hospitals-banks-personal.html
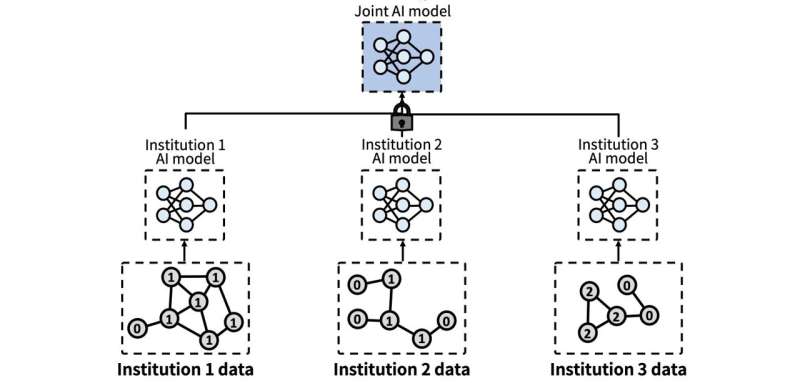
Federated learning was devised to solve the problem of difficulty in aggregating personal data, such as patient medical records or financial data, in one place. However, during the process where each institution optimizes the collaboratively trained AI to suit its own environment, a limitation arose: The AI became overly adapted to the specific institution’s data, making it vulnerable to new data.
A research team has presented a solution to this problem and confirmed its stable performance not only in security-critical fields like hospitals and banks but also in rapidly changing environments such as social media and online shopping.
The research team led by Professor Chanyoung Park of the Department of Industrial and Systems Engineering developed a new learning method that fundamentally solves the chronic performance degradation problem of federated learning, significantly enhancing the generalization performance of AI models. The work is published on the arXiv preprint server.
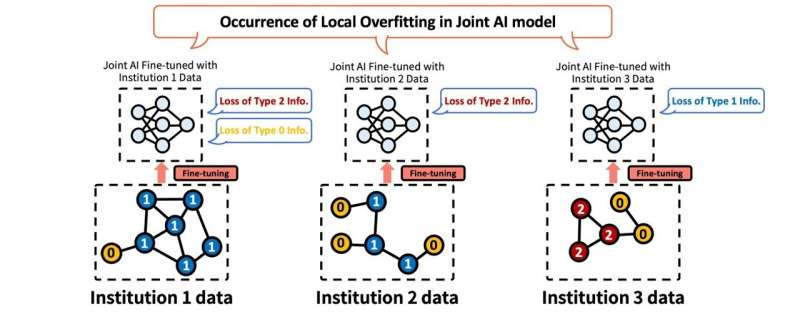
The Local Overfitting problem occurs during the process of fine-tuning the ‘Joint AI Model’ built through Federated Learning with each institution’s data. For example, Institution 3 can fine-tune the joint AI with its own data (Type 0, 2) to create an expert AI for those types, but in the process, it forgets the knowledge about data (Type 1) that other institutions had (Information Loss). In this way, each institution’s AI becomes optimized only for its own data, gradually losing the ability (generalization performance) to solve other types of problems that were obtained through collaboration. Credit: The Korea Advanced Institute of Science and Technology (KAIST)
Federated learning is a method that allows multiple institutions to jointly train an AI without directly exchanging data. However, a problem occurs when each institution fine-tunes the resulting joint AI model to its local setting. This is because the broad knowledge acquired earlier is diluted, leading to a local overfitting problem where the AI becomes excessively adapted only to the data characteristics of a specific institution.
For example, if several banks jointly build a “collaborative loan review AI,” and one specific bank performs fine-tuning focusing on corporate customer data, that bank’s AI becomes strong in corporate reviews but suffers from local overfitting, leading to degraded performance in reviewing individual or startup customers.
Professor Park’s team introduced the synthetic data method to solve this. They extracted only the core and representative features from each institution’s data to generate virtual data that does not contain personal information and applied this during the fine-tuning process. As a result, each institution’s AI can strengthen its expertise according to its own data without sharing personal information, while maintaining the broad perspective (generalization performance) gained through collaborative learning.
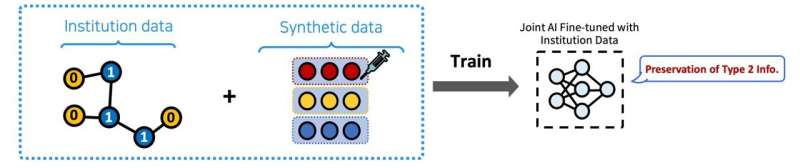
The technology proposed by the research team solves the local overfitting problem by utilizing Synthetic Data. When each institution fine-tunes its AI with its own data, it simultaneously trains with ‘Global Synthetic Data’ created from the data of other institutions. This synthetic data acts as a kind of ‘Vaccine’ to prevent the AI from forgetting information not present in the local data (e.g., Type 2 in the image), helping the AI to gain expertise on specific data while retaining a broad view (generalization performance) to handle other types of data. Credit: The Korea Advanced Institute of Science and Technology (KAIST)
The research results showed that this method is particularly effective in fields where data security is crucial, such as health care and finance, and also demonstrated stable performance in environments where new users and products are continuously added, like social media and e-commerce. It proved that the AI could maintain stable performance without confusion even if a new institution joins the collaboration or data characteristics change rapidly.
Professor Chanyoung Park of the Department of Industrial and Systems Engineering said, “This research opens a new path to simultaneously ensure both expertise and versatility for each institution’s AI while protecting data privacy. It will be a great help in fields where data collaboration is essential but security is important, such as medical AI and financial fraud detection AI.”
More information: Sungwon Kim et al, Subgraph Federated Learning for Local Generalization, arXiv (2025). DOI: 10.48550/arxiv.2503.03995
Journal information: arXiv
Leave a Reply