September 18, 2025 r by Paul Arnold, Phys.org
Collected at: https://techxplore.com/news/2025-09-ai-problems-humans-required.html
Artificial intelligence is getting smarter every day, but it still has its limits. One of the biggest challenges has been teaching advanced AI models to reason, which means solving problems step by step. But in a new paper published in the journal Nature, the team from DeepSeek AI, a Chinese artificial intelligence company, reports that they were able to teach their R1 model to reason on its own without human input.
When many of us try to solve a problem, we typically don’t get the answer straight away. We follow a methodical process that may involve gathering information and taking notes until we get to a solution. Traditionally, training AI models to reason has involved copying our approach. However, it is a long, drawn-out process where people show an AI model countless examples of how to work through a problem. It also means that AI is only as good as the examples it is given and can pick up on human biases.
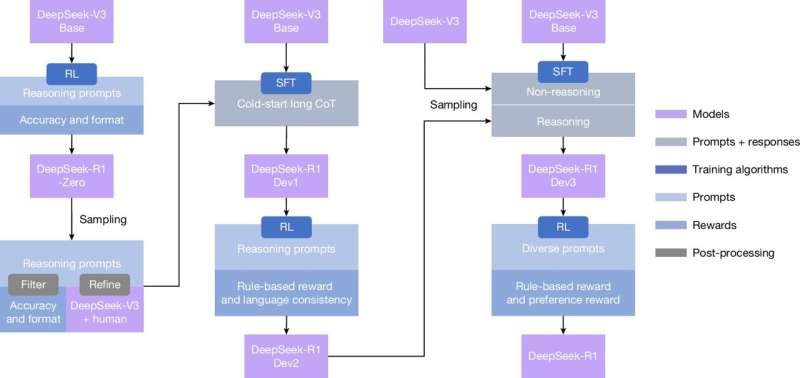
Instead of showing the R1 model every step, researchers at DeepSeek AI used a technique called reinforcement learning. This trial-and-error approach, using rewards for correct answers, encouraged the model to reason for itself.
“Rather than explicitly teaching the model how to solve a problem, we simply provide it with the right incentives and it autonomously develops advanced problem-solving strategies,” wrote the researchers in their paper.
DeepSeek’s R1 model was trained on difficult math, coding and science problems. The only reward it received was a signal that its final answer was correct. During its training, the researchers saw it develop skills such as checking its own work and exploring different strategies to find a solution. It even started to use words like “wait” as it reflected on its own thinking process. If a path led to the right answer, that strategy was reinforced. If it was wrong, the model learned not to repeat it. There was some human intervention, but only to polish R1’s skills later in the process.
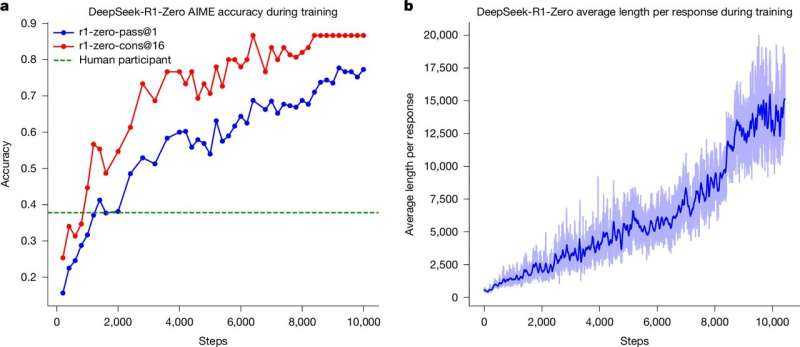
Accuracy and output length of DeepSeek-R1-Zero throughout the training process. Credit: Nature (2025). DOI: 10.1038/s41586-025-09422-z
The results were impressive. R1 performed better on math, coding and science tasks than older models trained with human guidance. One of the most noteworthy results was that it achieved an accuracy of 86.7% on the American Invitational Mathematics Examination (AIME) 2024, a tough math competition for the smartest high school students.
Even with these outstanding results, the researchers admit their model has some limitations to work through. For example, it sometimes mixed languages when given a non-English prompt and made some simple problems more complicated than they needed to be. But once these issues are ironed out, the researchers believe that an AI model that can reason for itself will lead to a new era of more capable and autonomous models.
More information: Daya Guo et al, DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning, Nature (2025). DOI: 10.1038/s41586-025-09422-z
Journal information: Nature
Leave a Reply