August 4, 2025 by Rakesh Kumar, PhD
Collected at: https://www.eeworldonline.com/what-are-the-hardware-strategies-for-building-energy-efficient-ai-accelerators/
Artificial intelligence (AI) applications are spreading to more industries every day. However, the amount of energy used by these AI systems has become a significant issue. Modern deep neural networks require a considerable amount of computing power.
This article examines five key hardware strategies for building energy-efficient AI acceleration: dedicated accelerator architectures, analog in-memory computing, heterogeneous computing systems, neuromorphic computing, and 3D chip stacking technologies.
Dedicated accelerators, hardware architectures
AI systems need special computer chips that work much better than regular CPUs when running AI models. Regular CPUs just can’t handle AI tasks efficiently enough and use too much power. To solve this problem, engineers have created four main types of dedicated accelerator architectures, as shown in Figure 1. Each type of hardware accelerator has its strengths and works best for different kinds of AI workloads:

- Graphics Processing Units (GPUs) feature thousands of parallel compute cores with high memory bandwidth, making them ideal for matrix operations common in deep learning. Their architecture includes specialized tensor cores that accelerate AI operations while maintaining flexibility across various frameworks.
- Neural Processing Units (NPUs) are specifically designed for AI inference, featuring multiple compute units optimized for matrix multiplication and convolution operations. Their architecture includes on-chip memory to reduce data transfer overhead and increase throughput, particularly excelling with convolutional neural networks.
- Field-Programmable Gate Arrays (FPGAs) offer millions of programmable gates that can be reconfigured for specific AI tasks. This flexibility allows optimization for particular neural network architectures while achieving low latency, making them valuable for real-time applications.
- Application-Specific Integrated Circuits (ASICs) offer the highest energy efficiency through custom-designed architectures specifically tailored for particular AI models. While lacking flexibility, they deliver superior performance per watt for dedicated applications.
Each architecture represents different trade-offs between flexibility, performance, and energy efficiency, allowing developers to select the optimal hardware strategy based on their specific AI inference requirements and deployment constraints.
Analog in-memory computing architectures
Analog in-memory computing (AIMC) addresses the von Neumann bottleneck by performing computations where data is stored, rather than moving information between separate processing and memory units. Figure 2 illustrates how phase-change memory (PCM) devices enable this approach through crossbar arrays that exploit fundamental physics principles.

Matrix-vector multiplications are the dominant operation in neural networks. These operations are executed using Ohm’s and Kirchhoff’s laws. Input voltages applied to word lines interact with stored conductance values to produce currents proportional to the desired computational results.
The AIMC tile architecture incorporates digital-to-analog converters and analog-to-digital converters. These components interface with digital systems while maintaining analog computational efficiency. This approach provides energy advantages by eliminating data movement overhead and enabling notable parallelism, with millions of operations executing simultaneously.
Non-volatile memory characteristics further reduce static power consumption. The ALPINE framework demonstrates these benefits across multiple neural network types, such as MLPs, CNNs, RNNs, and LSTMs. It leads to achieving up to 20.5x performance speedups and 20.8x energy improvements compared to traditional implementations. However, challenges remain in managing precision limitations and device variability.
Heterogeneous computing architectures
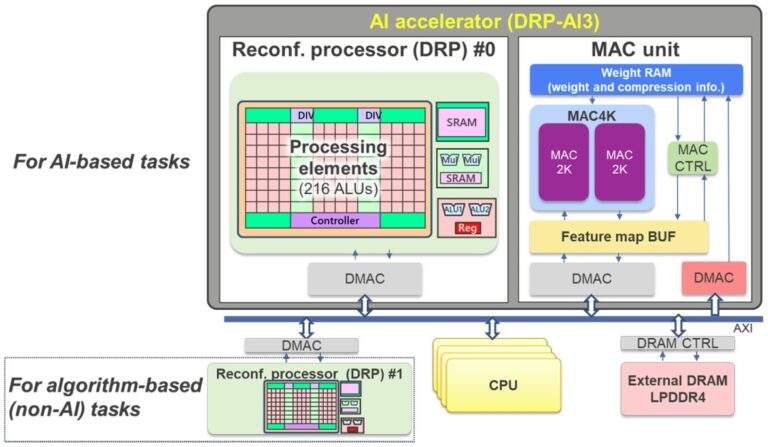
Heterogeneous computing architectures improve energy efficiency by deploying multiple specialized processing units that cooperatively handle different aspects of AI workloads. Figure 3 illustrates Renesas’s DRP-AI3 implementation, where an AI accelerator works alongside a dynamically reconfigurable processor (DRP) and traditional CPU cores. This approach recognizes that AI applications require diverse computational patterns. These range from neural network inference to algorithm-based processing and system control. Each pattern is optimized for different hardware types.

The AI accelerator component handles compute-intensive neural network operations with dedicated MAC units and optimized dataflows, while the reconfigurable DRP processor dynamically adapts its circuit configuration for streaming data processing, image preprocessing, and pooling operations. The CPU manages system-level tasks and provides programming flexibility.
This division of labor enables each processing unit to operate efficiently within its specialized domain, thereby avoiding the energy penalties associated with forcing general-purpose hardware to handle specialized tasks. The cooperative design achieves notable results, with hardware-software coordination delivering up to 10 times performance improvements while maintaining flexibility for diverse AI model types.
Multi-threaded pipelining across the heterogeneous components further optimizes resource utilization, demonstrating how strategic task partitioning can enhance overall system energy efficiency.
Neuromorphic computing
Neuromorphic computing copies how the human brain uses energy. This brain-inspired method changes how we build computers by using memristors as electronic synapses. These memristors combine the jobs that processing and memory usually do separately. Figure 4 shows how three-dimensional neuromorphic architectures build distributed computing networks. In these systems, memristive devices work as both storage and computational elements at the same time. This approach creates non-von Neumann systems that work very differently from regular computers.

The 3D implementation offers advantages over traditional 2D approaches by providing high connectivity between neuron layers while addressing routing congestion issues that affect conventional designs. Memristive synapses enable parallel data processing with adaptive learning capabilities, processing information in an event-driven manner similar to biological neural networks.
This architecture supports various neuromorphic computing approaches, including distributed, centralized, and adaptive neuromorphic computing architectures.
Survey data indicates that spiking neural network accelerators demonstrate improved energy efficiency, consuming an average of 0.9 watts compared to 1.7 watts for non-spiking implementations. It makes neuromorphic computing well-suited for low-power edge applications requiring intelligent, adaptive behavior.
3D chip stacking
Three-dimensional chip stacking addresses the physical limitations of planar semiconductor scaling while improving energy efficiency through reduced interconnect distances. Figure 5 illustrates two primary 3D RRAM integration strategies: horizontal 3D RRAM (H-RRAM) and vertical 3D RRAM (V-RRAM) structures that extend traditional 2D crossbar arrays into the third dimension. This vertical scaling achieves significant improvements in device density through area scaling.

The energy efficiency gains stem from shortened signal paths and reduced interconnect capacitance, directly lowering power consumption while enabling high-connectivity systems. Through-silicon vias facilitate inter-layer communication, creating parallel data processing capabilities suitable for dense neural network implementations.
V-RRAM architectures prove particularly cost-effective as layer count increases. The number of critical lithography masks remains relatively independent of stacking layers. This differs from H-RRAM, where mask requirements scale linearly. This 3D method lets memory and processing elements be combined into a single block. This enables neural network accelerators with higher density and improved energy efficiency for next-generation AI applications that require compactness and speed.
Summary
Building energy-efficient AI accelerators includes many hardware strategies. These range from dedicated architectures and analog in-memory computing to heterogeneous systems, neuromorphic designs, and 3D integration technologies. The future of AI acceleration lies in smartly combining various techniques. Success will depend on hardware-software co-design. This means that algorithm optimization and hardware capabilities must develop in tandem to improve the energy efficiency of AI systems.
Leave a Reply