March 12, 2026 by Ingrid Fadelli, Phys.org
Collected at: https://techxplore.com/news/2026-03-human-brain-ai-speech-recognition.html
Over the past decades, computer scientists have developed numerous artificial intelligence (AI) systems that can process human speech in different languages. The extent to which these models replicate the brain processes via which humans understand spoken language, however, has not yet been clearly determined.
Researchers at Columbia University, IBM Research and the Feinstein Institutes for Medical Research recently carried out a study aimed at comparing how automatic speech recognition (ASR) systems and the human brain decode speech. Their findings, published in Nature Machine Intelligence, suggest that activity in specific brain regions while people make sense of spoken language corresponds to specific stages in the processing of speech by AI models.
“The core mystery we wanted to solve is how the human brain performs the incredible computational feat of turning raw acoustic vibrations, the sounds of speech, into discrete linguistic meaning,” Nima Mesgarani, senior author of the paper, told Tech Xplore. “We now have AI systems that match human performance in transcribing speech, but we didn’t know if they were reaching those solutions independently or if they had converged on the same strategy as our biology.”
Matching brain activity to the speech processing of AI
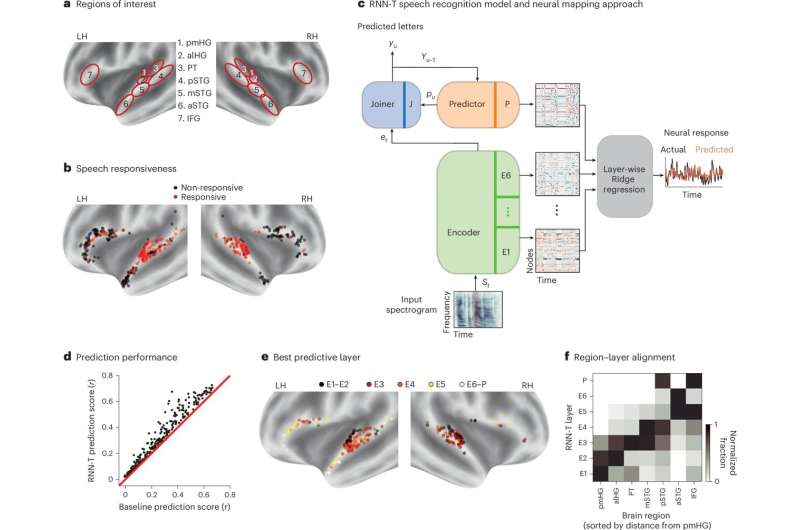
The primary goal of the recent work by Mesgarani, Menoua Keshishian (first author of the paper) and their colleagues was to determine whether AI models and the human brain transform sounds into meaning via similar fundamental computational strategies or not. To do this, they compared the internal representations of recurrent neural networks (RNNs) trained to recognize speech with brain activity recorded from 15 patients who were being monitored as part of their treatment for epilepsy.
“These patients had high-resolution electrodes implanted directly in their auditory cortex to locate abnormal brain activity,” explained Mesgarani. “While being monitored, they volunteered to listen to 30 minutes of continuous spoken stories.”
The researchers extracted the recordings collected in the brains of the study participants while they were listening to narrated stories, then compared them to the internal states of AI systems that were processing audio recordings of the same stories. The AI systems considered in their study were RNNs, computational models that are designed to mimic the architecture of biological neural networks.
“Unlike many common AI models (like transformers used in large language models), the RNN we employed is ‘causal,’ meaning that it processes speech step-by-step as it happens, much like the human brain,” said Mesgarani. “We played the same stories for the AI and looked at its internal states across every layer of the program. By using regression methods, we could see if specific ‘layers’ of the AI acted as a digital subspace for specific ‘neighborhoods’ in the brain. We tested everything from raw pitch to complex semantic meaning.”
Interestingly, Mesgarani, Keshishian and their colleagues found that the hierarchy with which the brain of the human participants processed the narrated stories resembled the step-by-step processing of speech by the RNN’s internal layers. In simple terms, both the AI model and the human brain appeared to progressively make sense of spoken language, ultimately decoding its meaning.
“Both systems follow a nearly identical sequence, progressing from basic acoustic features to phonetic, then lexical (words), and finally semantic information,” explained Mesgarani. “As you move deeper into the AI’s layers, the information maps topographically to the human cortical hierarchy, moving from the primary auditory core outward to higher-order language regions. This suggests that this specific hierarchical transformation is likely a robust, efficient computational solution discovered by both biological evolution and task-optimized AI.”
Avenues for further research and AI development
The results of this recent study suggest that ASR models, particularly RNNs, process speech via computational strategies that closely resemble brain processes. In the future, they could inspire further efforts aimed at comparing how the human brain and specific AI models tackle different tasks in even greater detail.
“By using models that finally match human performance, we can treat them as a ‘transparent’ version of the brain to understand its computational principles,” said Mesgarani. “However, this is just the beginning. While our AI model is a single pathway, the brain is strikingly lateralized; the left hemisphere is far more dominant for high-level language tasks. We still need to understand why biology prefers this ‘two-sided’ split and whether building ‘dual pathway’ AI models will reveal new insights into how we handle complex communication.”
Notably, the brain-like computational strategy observed by these researchers was found to only emerge in RNNs if the models were trained on speech in a specific language. As part of their next studies, they would like to further explore this observation and determine whether it could mirror how the brain processes native or foreign languages.
“We wonder: Does a brain trained on one language process a second language using the same ‘hardware’ but a different ‘software’ strategy?” added Mesgarani. “Our final goal isn’t just to make better AI, but to use these models as an explicit hypothesis for how the brain solves the sound-to-meaning problem. We are moving toward a future where we can simulate the brain’s language processing to understand exactly what makes our biological intelligence unique, and how this process can become impaired.”
Publication details
Menoua Keshishian et al, Parallel hierarchical encoding of linguistic representations in the human auditory cortex and recurrent automatic speech recognition systems, Nature Machine Intelligence(2026). DOI: 10.1038/s42256-026-01185-0
Journal information: Nature Machine Intelligence
Leave a Reply