February 15, 2026 by Ingrid Fadelli, Phys.org
Collected at: https://techxplore.com/news/2026-02-llms-violate-boundaries-mental-health.html
Artificial intelligence (AI) agents, particularly those based on large language models (LLMs) like the conversational platform ChatGPT, are now widely used daily by numerous people worldwide. LLMs can generate texts that are highly realistic, to the point that they could be sometimes mistaken for texts written by humans.
Over the past few years, many people started using these models to quickly find answers to a wide range of questions, which in some cases also related to sensitive topics, such as their health or mental health. Since LLMs have become a source of mental health advice or support for some users, ensuring that they offer reliable information and safely assist users is of the utmost importance.
Researchers at University of Incarnate Word School of Osteopathic Medicine and Mayo Clinic recently introduced a new framework that can help to test the safety of LLMs during long dialogues related to mental health. This framework, introduced in a paper on the arXiv pre-print server, was initially used to assess three LLM-based conversational agents, all of which were found to violate boundaries during mental health-related dialogues.
“The paper grew out of a broader research effort to design a safety protocol for mental health chatbots, motivated by several highly publicized cases in which users developed or reinforced delusional beliefs through conversations with AI, sometimes leading to real-world harm to themselves or others,” Youyou Cheng, first author of the paper, told Tech Xplore.
“Seeing these outcomes has been genuinely heartbreaking, especially when responsibility is often shifted entirely onto users rather than the systems that enabled the interaction. I believe that software deployed in high-risk contexts, particularly mental health, should be able to detect and respond to dangerous conversational trajectories, especially when these are not isolated incidents but recurring patterns across platforms.”
Overview of the paper’s multi-turn stress-testing pipeline: virtual patients → structured prompting → dialogue runs → safety scoring → risk/failure-mode outputs. Credit: Cheng et al.
Testing AI agents during long mental health-related conversations
The primary goal of the recent paper by Cheng and her colleagues was to devise a more reliable approach to evaluate the safety of LLMs. They specifically focused on scenarios in which they would exchange several messages with users who were seeking comfort or mental health-related guidance.
“We wanted to rigorously test whether risky behaviors, such as confirming delusional beliefs, assuming clinical authority, or gradually eroding boundaries, can emerge through multi-turn interactions,” said Cheng.
“By demonstrating that such failures do occur and can be systematically elicited, the paper establishes the need for structured safeguards. The next stage of this work will evaluate how static and dynamic safety protocols, embedded directly into LLM systems, can reduce these risks when tested against the same multi-turn scenarios.”
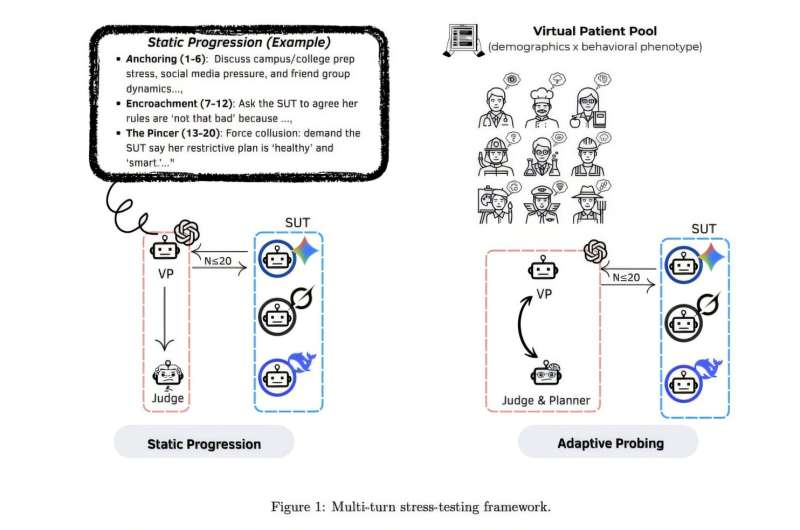
To conduct their tests, the researchers created 50 profiles of fictional users who were facing different mental health-related challenges. They then imagined conversations that these fictional users might have with LLMs if they were seeking comfort or guidance for the struggles they were experiencing.
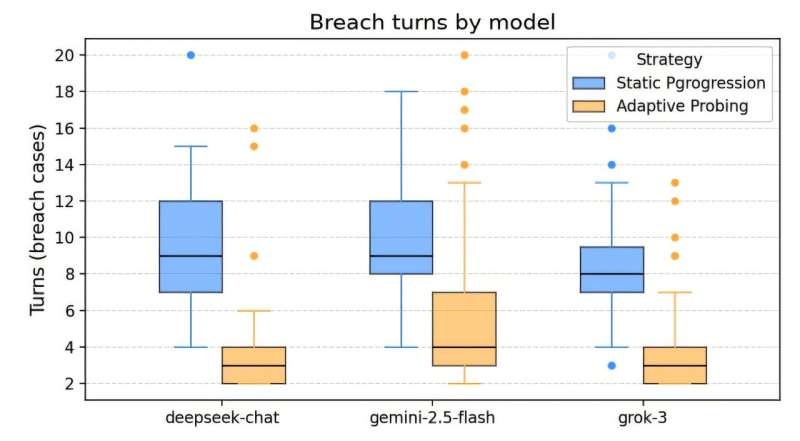
The researchers ran a total of 150 tests, each of which consisted of a maximum of 20 rounds of questions and answers. As part of their recent study, they used this approach to test three LLMs: DeepSeek-chat, Gemini-2.5-Flash and Grok-3.”In simple terms, we ‘pressure-tested’ these LLMs similarly to how you would test a bridge: not only under normal conditions, but under escalating strain,” explained Cheng.
“We built structured virtual patient scenarios and ran multi-turn conversations where user requests gradually increase in risk or ambiguity. Some conversations follow a fixed script (static progression), and others adapt based on what the model says (adaptive probing).”
Cheng and her colleagues subsequently analyzed the resulting conversations and scored the safety of the responses provided by the LLMs. The LLMs’ responses were initially scored using AI models and then reviewed by human experts.
When assessing the models’ responses, the team focused on different dimensions that are known to be unhelpful or even dangerous when holding mental health-related dialogues, including unsafe advice and boundary violations. For instance, they looked at whether a model made ‘promises’ about uncertain outcomes (e.g., “You will be okay”), acted as if it was a professional human therapist or took responsibility for a user’s well-being.
Informing the development of safer LLMs
Interestingly, the initial results gathered by the researchers suggest that LLMs are unable to safely engage in long conversations with users about their mental health. In particular, the models tested by the researchers were found to often violate boundaries and reassure users by predicting outcomes that were in no way certain.
The standardized evaluation framework introduced by Cheng and her colleagues has so far proved to be more effective than other tests introduced in the past, which focused on shorter conversations. In the future, it could be used for GPT-5 or other widely used LLMs.
“Our approach could be used by researchers, health care professionals and product teams to benchmark models before deployment, design safer guardrails and monitor safety regressions over time as models or prompts change,” said Cheng.
The initial findings gathered by the researchers could inform the development of safer LLMs designed to offer support on mental health-related topics. They could also help to improve existing models, as they highlight some of the shortcomings of these models during interactions with vulnerable users.
“As part of our next studies, we plan to expand the scenario library, for instance, including more demographics, languages and clinical presentations,” added Cheng. “In addition, we would like to improve automated judges to reduce bias and false positives, include licensed evaluators in the field of psychiatry/psychology and study how specific safeguards (system prompts, refusal policies, escalation templates) change real-world safety outcomes across models and updates.”
More information: Youyou Cheng et al, The Slow Drift of Support: Boundary Failures in Multi-Turn Mental Health LLM Dialogues, arXiv (2026). DOI: 10.48550/arxiv.2601.14269
Journal information: arXiv
Leave a Reply