December 22, 2025 by Andrew Clark, Cornell University
Collected at: https://techxplore.com/news/2025-12-vision-method-links-photos-floor.html
For people, matching what they see on the ground to a map is second nature. For computers, it has been a major challenge. A Cornell research team has introduced a new method that helps machines make these connections—an advance that could improve robotics, navigation systems, and 3D modeling.
The work, presented at the 2025 Conference on Neural Information Processing Systems and published on the arXiv preprint server, tackles a major weakness in today’s computer vision tools. Current systems perform well when comparing similar images, but they falter when the views differ dramatically, such as linking a street-level photo to a simple map or architectural drawing.
The new approach teaches machines to find pixel-level matches between a photo and a floor plan, even when the two look completely different. Kuan Wei Huang, a doctoral student in computer science, is the first author; the co-authors are Noah Snavely, a professor at Cornell Tech; Bharath Hariharan, an associate professor at the Cornell Ann S. Bowers College of Computing and Information Science; and undergraduate Brandon Li, a computer science student.
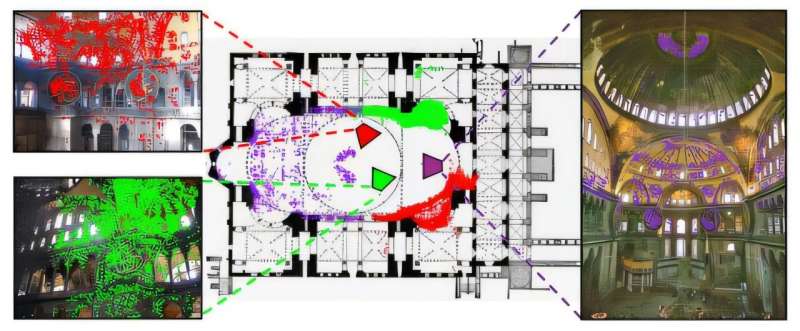
The team nicknamed the new model C3Po—shorthand for its full title, “Cross-View Cross-Modality Correspondence by Pointmap Prediction,” and a playful nod to the Star Wars character. To support it, the team created C3, a massive dataset of paired photos and floor plans. This resource trains computers to understand how real-world images relate to simplified maps—a critical capability for such technologies as indoor navigation, robotic movement, and digital reconstruction of spaces.
“There have been huge advances in 3D computer vision recently, reminiscent of the breakthroughs that large language models had with language a few years ago,” said Snavely, who is also affiliated with Cornell Bowers. “We now have large machine learning models that can take 2D images—for instance, a handful of images of a building—and produce a 3D reconstruction of that place.”
He explained that current large-scale vision models are limited because they’ve only been trained on photographs. When given an image outside that domain, such as a floor plan, they perform poorly, simply because they’ve never encountered that type of input.
“A big factor in this problem is limited data,” he said. “So, we wanted to create a dataset that links floor plans with normal photographs, and that’s what became the C3 dataset.”
To fill this gap, the team created C3, a dataset comprising 90,000 floor-plan and photo pairs across 597 scenes, including 153 million pixel-level correspondences and 85,000 camera poses. They assembled the dataset by reconstructing each scene in 3D from large internet photo collections, then manually aligning these reconstructions to publicly available floor plans. This alignment enables precise mapping between image pixels and floor-plan coordinates, something no previous dataset supported at scale.
When the team tested existing methods, most struggled with this task, often making mistakes bigger than 10% of the image. To fix that, the researchers refined their approach so the system could match each pixel in a photo to a precise point on the floor plan. Their improved model, C3Po, cut errors by 34% compared with the best previous method and delivered more reliable results when the system was confident in its predictions.
“In the long run, we hope that this will inspire large 3D computer vision models that can take all sorts of inputs relating to a scene,” Snavely said. “The 3D computer vision research domain is usually a few years behind other areas in terms of utilizing the latest trends from the field of AI, and I personally think this multi-modal direction that AI is going in will soon be a new frontier in 3D computer vision as well.”
More information: Kuan Wei Huang et al, C3Po: Cross-View Cross-Modality Correspondence by Pointmap Prediction, arXiv (2025). DOI: 10.48550/arxiv.2511.18559
Journal information: arXiv
Leave a Reply