December 14, 2025 by Ingrid Fadelli, Phys.org
Collected at: https://techxplore.com/news/2025-12-ai-agents-debate-mathematical.html
Large language models (LLMs), artificial intelligence (AI) systems that can process and generate texts in various languages, are now widely used worldwide to create written content, source information and even to code websites or applications. While these models have improved significantly over the past couple of years, their answers can sometimes contain factual inaccuracies or logical inconsistencies.
In other words, in some cases LLMs produce answers to users’ questions that appear to be reliable, yet they contain false information, contradictory statements or logical inconsistencies. This observed tendency makes them unreliable, limiting their potential for sourcing accurate information or preparing documents, particularly in educational and professional settings.
Researchers at South China Agricultural University and Shanghai University of Finance and Economics recently introduced a new framework that was found to improve the mathematical reasoning abilities and reliability of LLMs. The new framework, introduced in a paper in the Journal of King Saud University Computer and Information Sciences, works by initiating debates between multiple LLMs, which try to reach a consensus about the answer they should give to a given question.
“Prior works have improved LLM performance using prompt-based techniques (e.g. chain-of-thought prompting and self-consistency) and post-hoc self-refinement, but these typically operate on a single model instance,” wrote Yan Zhou and Yanguang Chen in their paper.
“Recently, multi-agent debate frameworks have emerged as a complementary approach, wherein multiple LLM agents propose answers and critique each other’s reasoning to reach consensus. Such a ‘society of minds’ approach has been shown to significantly improve mathematical reasoning and reduce factual hallucinations. However, existing debate methods use homogeneous agents with simple majority voting, limiting their effectiveness.”
Boosting LLM reasoning via multi-agent debates
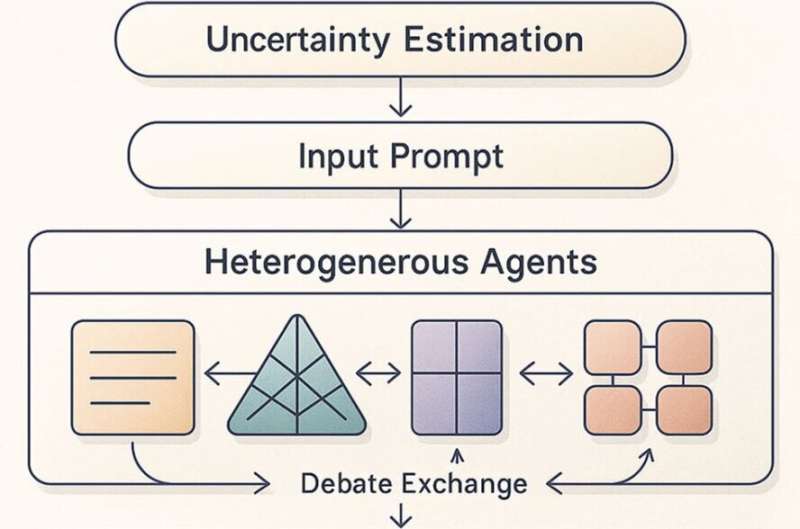
To reduce the factual and logical flaws in the answers provided by LLMs, the team developed a framework called Adaptive Heterogeneous Multi-Agent Debate (A-HMAD). Essentially, it suggests prompting debates between multiple AI agents with different specialties, dynamically modulating their discussion and prompting them to reach a consensus on a given topic.
“Each agent in A-HMAD is assigned a distinct role or expertise (e.g. logical reasoning, factual verification, strategic planning), enabling more comprehensive error-checking and perspective diversity than identical agents,” wrote Zhou and Chen. “A coordination policy dynamically selects which agents contribute at each round based on the question’s domain and the evolving debate state.”
To weigh the arguments made by the different LLMs and ensure that they produce the most accurate and logically sound response to a query, the team developed a consensus optimizer. This is a tool that rates each of the agents’ contributions based on their reliability and its overall confidence in the information they include.
Initial results and possible future applications
Zhou and Chen tested their proposed framework using six different types of problems that are challenging for both AI models and some humans. In addition, they performed trials where they removed or altered some of the framework’s underlying components, to assess how these changes influenced its performance.
“On six challenging benchmarks—including arithmetic QA, grade-school math (GSM8K), multifact question answering (MMLU), factual biography generation, and chess strategy—our A-HMAD consistently outperforms prior single-model methods and the original multi-agent debate baseline,” wrote Zhou and Chen.
“Notably, A-HMAD achieves 4–6% absolute accuracy gains over standard debate on these tasks, and reduces factual errors by over 30% in biography facts. We provide extensive ablations demonstrating the benefits of agent heterogeneity, additional debate rounds, and the learned consensus module.
In initial tests, the team’s framework was found to yield more factually accurate and logically sound responses than the individual LLMs and alternative debate-based approaches that it was compared to. In the future, the framework could be improved further and used to develop a more reliable AI platform that could be used by teachers, professors, scientists, and other professionals to rapidly source correct answers to complex questions.
“Our findings suggest that an adaptive, role-diverse debating ensemble can drive significant advances in LLM-based educational reasoning, paving the way for safer, more interpretable, and pedagogically reliable AI systems,” concluded the authors.
More information: Yan Zhou et al, Adaptive heterogeneous multi-agent debate for enhanced educational and factual reasoning in large language models, Journal of King Saud University Computer and Information Sciences (2025). DOI: 10.1007/s44443-025-00353-3
Leave a Reply