November 14, 2025 by Paul Arnold, Phys.org
Collected at: https://phys.org/news/2025-11-ai-math-genius-accurate-results.html
At the 2024 International Mathematical Olympiad (IMO), one competitor did so well that it would have been awarded the Silver Prize, except for one thing: it was an AI system. This was the first time AI had achieved a medal-level performance in the competition’s history. In a paper published in the journal Nature, researchers detail the technology behind this remarkable achievement.
The AI is AlphaProof, a sophisticated program developed by Google DeepMind that learns to solve complex mathematical problems. The achievement at the IMO was impressive enough, but what really makes AlphaProof special is its ability to find and correct errors. While large language models (LLMs) can solve math problems, they often can’t guarantee the accuracy of their solutions. There may be hidden flaws in their reasoning.
AlphaProof is different because its answers are always 100% correct. That’s because it uses a specialized software environment called Lean (originally developed by Microsoft Research) that acts like a strict teacher verifying every logical step. This means the computer itself verifies answers, so its conclusions are trustworthy.
Three-stage training process
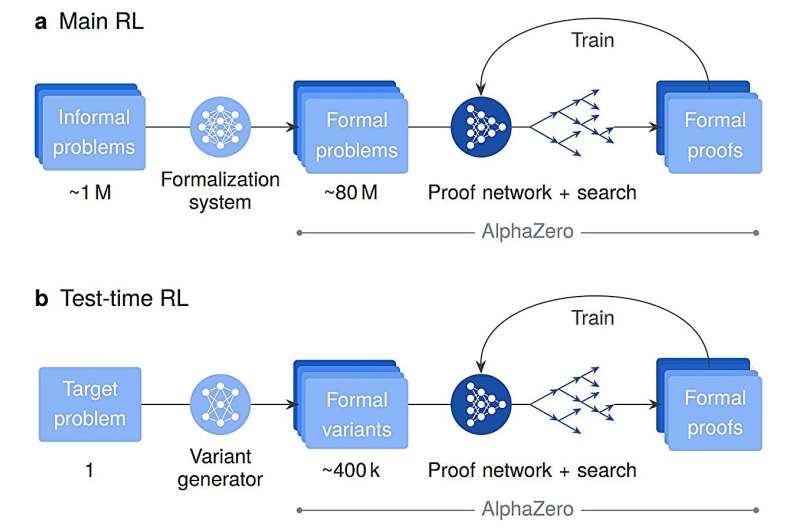
Training this powerful system to reason at an elite level involved three different training stages. First, the researchers exposed AlphaProof to about 300 billion tokens of general code and mathematical text to give it a broad understanding of concepts such as logic, mathematical language, and programming structure. Next, it was given 300,000 math proofs written by experts that were already in the Lean environment.
The final stage was where the system learned to solve problems on its own. It was given a massive homework task of 80 million formal math problems to solve. Using Reinforcement Learning (RL), which is based on trial and error, AlphaProof was rewarded for every successful proof. By tackling math problems on such a massive scale, the system taught itself new and complex reasoning strategies that went beyond copying human examples.
For the toughest problems, AlphaProof used a technique the researchers developed called Test-Time RL (TTRL), which creates and solves millions of simplified versions of the target problem until it finds a solution.
“Our work demonstrates that learning at scale from grounded experience produces agents with complex mathematical reasoning strategies, paving the way for a reliable AI tool in complex mathematical problem-solving,” wrote the researchers in their paper.
In addition to solving seemingly intractable math problems, AlphaProof could also be employed by mathematicians to correct their work and help them develop new theories.
More information: Thomas Hubert et al, Olympiad-level formal mathematical reasoning with reinforcement learning, Nature (2025). DOI: 10.1038/s41586-025-09833-y
Journal information: Nature
Leave a Reply