July 21, 2025 by Sejong University
Collected at: https://techxplore.com/news/2025-07-scalable-enables-device-large-language.html
Large language models (LLMs) like BERT and GPT are driving major advances in artificial intelligence, but their size and complexity typically require powerful servers and cloud infrastructure. Running these models directly on devices—without relying on external computation—has remained a difficult technical challenge.
A research team at Sejong University has developed a new hardware solution that may help change that. The work is published in the journal Electronics.
Their Scalable Transformer Accelerator Unit (STAU) is designed to execute various transformer-based language models efficiently on embedded systems. It adapts dynamically to different input sizes and model structures, making it especially well-suited for real-time on-device AI.
At the heart of the STAU is a Variable Systolic Array (VSA) architecture, which performs matrix operations—the core workload in transformer models—in a way that scales with the input sequence length. By feeding input data row by row and loading weights in parallel, the system reduces memory stalls and improves throughput. This is particularly important for LLMs, where sentence lengths and token sequences vary widely between tasks.
In benchmark tests published in Electronics, the accelerator demonstrated a 3.45× speedup over CPU-only execution while maintaining over 97% numerical accuracy. It also reduced total computation time by more than 68% when processing longer sequences.
Since then, continued optimizations have further improved the system’s performance: according to the team, recent internal tests achieved a speedup of up to 5.18×, highlighting the architecture’s long-term scalability.
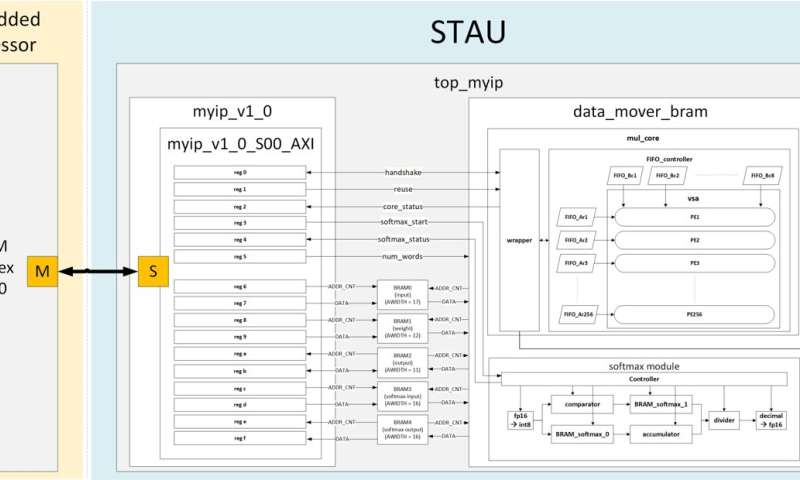
Top module architecture. Credit: Electronics (2024). DOI: 10.3390/electronics13234683
The researchers also re-engineered a critical part of the transformer pipeline: the softmax function. Typically a bottleneck due to its reliance on exponentiation and normalization, it was redesigned using a lightweight Radix-2 approach that relies on shift-and-add operations. This reduces the hardware complexity without compromising output quality.
To further simplify computation, the system uses a custom 16-bit floating-point format specifically tailored for transformer workloads. This format eliminates the need for layer normalization—another common performance bottleneck—and contributes to a more efficient, streamlined datapath.
STAU was implemented on a Xilinx FPGA (VMK180) and controlled by an embedded Arm Cortex-R5 processor. This hybrid design allows developers to support a range of transformer models—including those used in LLMs—by simply updating software running on the processor, with no hardware modifications required.
The team sees their work as a step toward making advanced language models more accessible and deployable across a broader range of platforms—including mobile devices, wearables, and edge computing systems—where real-time AI execution, privacy, and low-latency response are essential.
“The STAU architecture shows that transformer models, even large ones, can be made practical for on-device applications,” said lead author Seok-Woo Chang. “It provides a foundation for building intelligent systems that are both scalable and efficient.”
More information: Seok-Woo Chang et al, Scalable Transformer Accelerator with Variable Systolic Array for Multiple Models in Voice Assistant Applications, Electronics (2024). DOI: 10.3390/electronics13234683
I simply needed to appreciate you yet again. I do not know what I would’ve carried out without these tactics shown by you regarding such a subject matter. It has been the daunting case for me, but taking a look at a new skilled technique you handled that made me to weep for fulfillment. I will be happier for the service and as well , expect you recognize what a powerful job you have been putting in instructing most people by way of your blog. Probably you haven’t come across any of us.
I beloved up to you’ll obtain carried out proper here. The sketch is tasteful, your authored subject matter stylish. nevertheless, you command get got an nervousness over that you wish be handing over the following. in poor health unquestionably come further earlier again as precisely the same just about very ceaselessly inside of case you protect this hike.
Leave a Reply